
The RankDB Project is working on efficiently supporting top-k and preference queries in Database Systems. We are interested in the various aspects of the problem including preference and rank specification, rank-aware data models, integrating ranking in practical query processors and optimizers, and adaptive processing of top-k queries in non-traditional environment.
- Overview
- Example1
- Example2
- The Rank-join Algorithm
- Rank-join Query Operators
- Rank-aware Query Optimization
- Ranking Algebra
- The RankSQL project
A rank-aware relational database system prototype
(Joint project with Chengkai Li and Kevin Chang from UIUC)
- Ad-hoc Ranking Aggregates
(Joint project with Chengkai Li and Kevin Chang from UIUC)
Overview [top]
Despite their robust and efficient data management capabilities, current database systems lack efficient means of handling of IR-style queries, which are dominant in many emerging applications. These types of queries pose several challenges to the design and implementation of database engines, especially with respect to query processing and optimization. For example, applications in multimedia and web databases have notions of proximity, ranking, and user feedback that have serious impact on the query model, which cannot be adequately handled by current query processing approaches. Two of the data management challenges posed by these emerging applications are the following:
-
Traditional Boolean-based query processing cannot reflect user preferences in both query formulation and/or query processing. In many applications, “ranking” the query results according to some user criteria is an integral part of the query semantics. Hence, the increasing importance and applicability of ranked data retrieval warrants an efficient support of ranking in practical database systems.
-
As more applications migrate to hand-held devices, sensor networks and the Internet, many of the assumptions we make about the availability of data are no longer valid, since these environments usually suffer from unexpected delays and frequent disconnections. Hence, query processing paradigms have to adapt to the continuous changes (and fluctuations) in the computing environments. Ranking queries are dominant in these new, “less-stable” environments. Hence, providing an adaptive processing mechanism for ranking queries has a direct effect on the adaptability of many new applications.
RankDB focuses on a number of research directions to address these challenges: (1) enabling ranked retrieval in current relational query processors as a first-class functionality; (2) extending rank-aware query processing beyond relational data models to text and semi-structured databases, which are becoming an integral part of current applications infrastructure; and (3) introducing new rank-aware query processing paradigms that offer a high degree of adaptability and scalability.
Example 1: Multimedia Retrieval by Contents [top]
In a video database system (VDBMS), users provide an example image and request the video objects (segments or snapshots) most similar to that image. The similarity is measured with respect to several extracted visual features, e.g., the color histograms, the color layout, the texture or the orientation of the edges. Similarity queries are well studied and can give the most similar objects according to each feature separately. A major challenge in all retrieval-by-contents applications is how to combine several rankings into one global ranking of database objects.
|
Ranking w.r.t edge orientation
|
|
The Query Image

The top 5 video shots w.r.t the three features combined using Rank-join
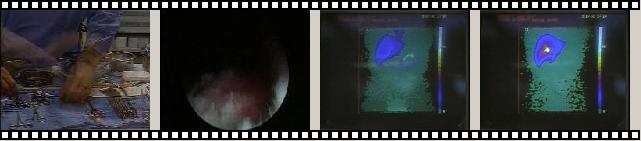
Figure 1: A multi-feature query in a multimedia retrieval by contents
Example 2: Ranking over External Sources [top]
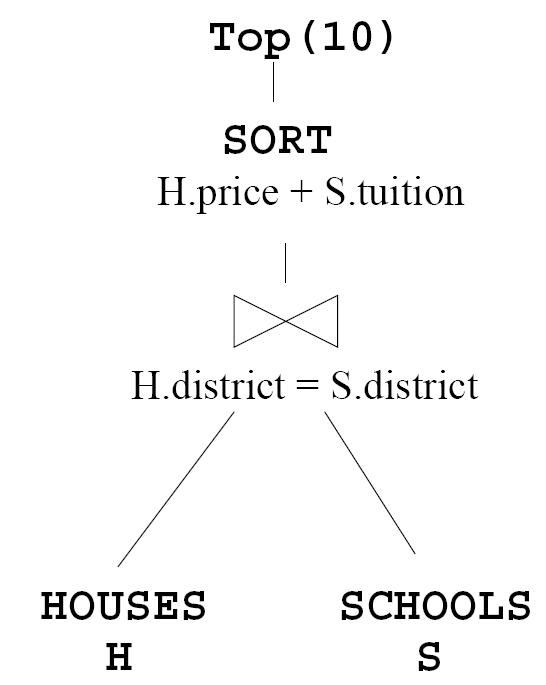
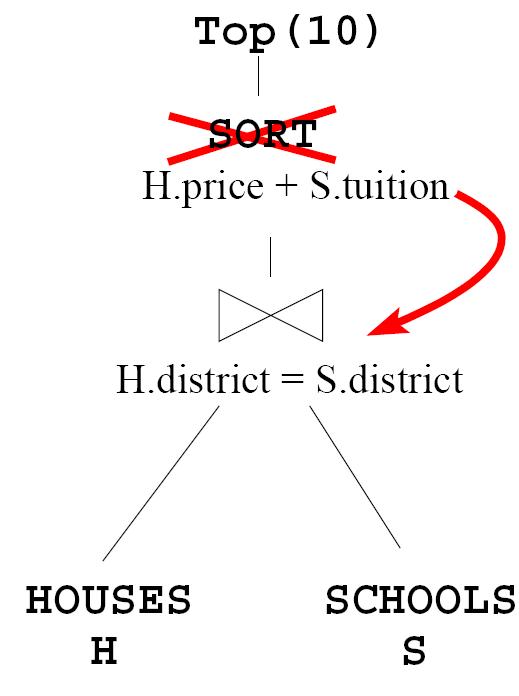
A user is interested in finding the most economic relocation choices by querying two available databases of Houses and Schools. The objective is to get the location with the lowest expenses, where the total expenses are computed as the sum of the price of the house and the school tuition for ten years. The simplest way to put this query in pseudo-SQL constructs is as follows:
SELECT H.id, S.name
FROM Houses H, Schools S
WHERE H.location = S.location
ORDER BY H.price + 10* S.tuition
LIMIT 10
Traditionally, the only way to answer this query is to compute all the join results (house-school pairs that are in the same location), then to sort the results according to the total cost. The solution is prohibitively expensive if the databases of houses and schools are very large or if the Houses and Schools are web databases or from external sources. Alternatively, if we can access the inputs from the two databases in a sorted access (ranked by house price and school tuition separately), my proposed rank-join algorithm produces the top k join results without consuming all the inputs. The performance benefit can be orders of magnitude over the traditional solution
In general, we focus on efficiently answering the general form of a top-k query given by the following query template, Q:
Q: SELECT some attributes
FROM R1,R2,.....,Rm
WHERE join condition
ORDER BY F(R1.score,R2.score,....,Rm.score)
LIMIT k
where F is a monotone function that combines the scores of individual inputs R1 .. Rm into one score for each join result.
The Rank-join Algorithm [top]
For simplicity, the algorithm is described for the binary case. Given two ranked inputs and a join condition, the rank-join algorithm produces the top k join results as soon as possible and without consuming all the inputs. The algorithm maintains a state which consists of a priority queue for buffering all join results that cannot yet be produced. The algorithm also maintains a threshold value that upper-bounds the scores of all "unseen" join results. Using the buffer and the threshold, the algorithm can decide if one of the produced join results is guaranteed to be among the top k answers. The rank-join algorithm is incremental in the sense that it reports the next top ranked result for each call of the algorithm. The main idea is to go in parallel (not necessarily in lock-step) in the inputs retrieving the next ranked tuple from each input and to join that tuple with all tuples seen so far.
Figure 2 gives an example execution of the algorithm for two inputs, L and R. The join condition is L.A = R.A. At some instance in the algorithm execution, the scores of the last tuple retrieved from the L and R are L_bottom and R_bottom, respectively. The scores of the top ranked tuples in L and R are L_top and R_top respectively. The threshold is computed as
T = Max (F(L_top,R_bottom) , F(L_bottom,R_top))
where F is the score combining function. In this example if F is the sum of scores, T = Max(100+3, 25+5) = 103. The join result J:[(1,1,100),(2,1,4)] is a valid join result that joins the first ranked tuple in L with the second ranked tuple in R and has the score of 100+4 = 104. Hence, J can be reported as the top ranked join result without continuing retrieving tuples from inputs, which can be arbitrary large.
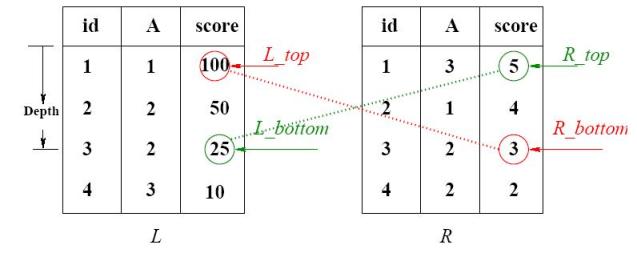
Figure2: The Rank-join Algorithm - the Binary Case
Rank-join Query Operators [top]
To support rank aggregation algorithms in a database
system, we have the choice of implementing these algorithms at the
application level as user-defined functions or to implement them as core
query operators (rank-join operators). Although the latter approach
requires more effort in changing
the core implementation of the query engine, it supports ranking as a
basic database functionality. In general, rank-join query
operators are physical join operators that, besides joining the inputs,
they produce the join results ranked according to a provided scoring
function.
Rank-join operators require the following:
-
the inputs (or at least one of them) are ranked and each input tuple has
an associated score, -
the input may not be materialized, but a GetNext interface on the input should retrieve the
next tuple in a descending order of the associated scores, and -
there is a monotone scoring function, say f, that computes a total score of the join result by applying f on the scores of the tuples from each input.
Rank-join operators are almost non-blocking. The next
ranked join result is usually produced in a pipelined fashion without
the need to exhaust all the inputs. On the other hand, a rank-join
operator may need to exhaust part of the inputs before being able to
report the next ranked join result. We proved that rank-join operators
can achieve a huge benefit over the traditional join-then-sort approach
to answer top-k join queries especially for small values of k.
We introduced two possible rank-join implementations: nested-loops rank-join (NRJN) and hash rank-join (HRJN). For any rank-join operator, the operator is initialized by specifying the two inputs, the join condition, and the combining function. HRJN can be viewed as a variant of the symmetrical hash join algorithm or the hash ripple join algorithm. HRJN maintains an internal state that consists of three structures. The first two structures are two hash tables, i.e., one for each input. The hash tables hold input tuples seen so far and are used in order to compute the valid join results. The third structure is a priority queue that holds the valid join combinations ordered on their combined score. NRJN is similar to HRJN except that it follows a nested-loops strategy to generate valid join results. NRJN internal states contains only a priority queue of all seen join combinations. Similar to HRJN, NRJN maintains a threshold that upper-bounds the scores of all unseen join results. The depth of a rank-join operator is defined as the number of input tuples needed to produce top-k join results
 |
 |
(a) (b)
Figure3: Pushing the Sorting into the Join in the Rank-join Algorithm
Rank-aware Query Optimization [top]
We introduce a rank-aware query optimization framework that fully integrates rank-join operators into relational query engines. We investigated two different ways to achieve this task:
(1) Extending Join Space Through Interesting Ranking Properties
The framework is based on extending the System R dynamic programming algorithm in both enumeration and pruning. We define ranking as an interesting property that triggers the generation of rank-aware query plans. Unlike traditional join operators, optimizing for rank-join operators depends on estimating the input cardinality of these operators. We introduce a probabilistic model for estimating the input cardinality, and hence the cost of a rank-join operator.
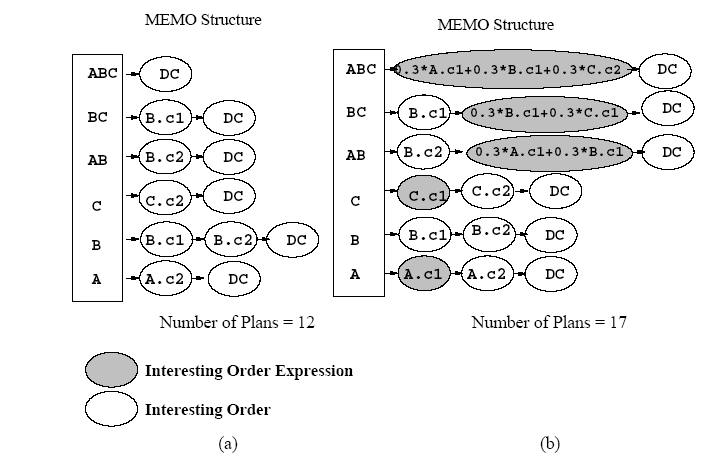
Figure4: Interesting Ranking Expressions
Figure 4 (a) gives the MEMO structure for the traditional application of the Dynamic Programming enumeration without the proposed extension. For example, we keep two plans for Table A; the cheapest plan that does not have any order property (DC) and the cheapest plan that produces results ordered on A.c2 as an interesting order. Figure 4 (b) shows the newly generated classes of plans that preserve the required ranking. For each interesting order expression, the cheapest plan that produces that order is retained. For example, in generating plans that join Tables A and B, we keep the cheapest plan that produces results ordered on 0.3*A.c1 + 0.3*B.c1.
(2) Two-Dimensional Space Enumeration With Sampling-based Statistics
We take a principled way to extend DP plan enumeration by treating ranking predicates as another dimension of enumeration in addition to Boolean predicates, based on the insight that the ranking (order) relationship is another logical property of data, parallel to membership. Recall that, ranked relation essentially possesses two logical properties: Boolean membership, and ranking order. In a ranking query plan, new ranking predicates are only introduced in operators. Therefore the predicate set of a sub-plan, determines the order, just like how join conditions (together with other operations) determine the membership.
To enable rank-aware query processing and optimization, we extend relational algebra to be rank-relational algebra, where the relations, operators, and algebraic laws respect and take advantage of the essential concept of rank. We define rank relational model and extend relational algebra. The new rank-relational algebra enables and determines our query execution model and operator implementations. We also introduce several laws of the new algebra to lay the foundation of query optimization.
(1) Rank-Relation

(2) Rank-Relational Operators
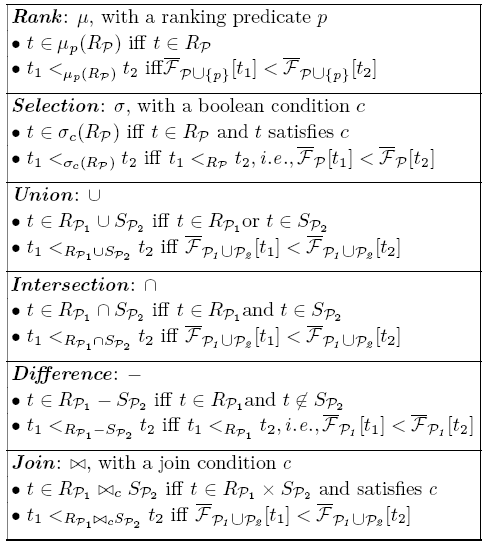
(3) Algebraic Equivalence Laws:
